开始的地方
当大家还在睡梦中时,大洋彼岸有一场“科技春晚”悄然召开。没错,又到了一年一度的GTC大会时刻。今年的GTC大会不同以往,终于恢复了线下举行,并且将从18号持续至21号。先给不了解GTC的玩家介绍一下,GTC是关于AI的NVIDIA开发者大会,会议中你可以了解如何利用AI、加速计算以及数据科学去塑造甚至是改变世界。

图片源于网络
今年的GTC峰会主题完全围绕AI展开,2个小时的时间,老黄又一次带来了AI的变革时刻。当然除了老黄的开幕演讲外,后面还有900多场鼓舞人心的会议在等着你。同时此次GTC大会还吸引了超过200家展商,汇聚了数千名不同行业领域的从业人员一同参与。丰富多彩的技术分享、越见非凡的创新技术,称它是AI的盛会都不为过。想必你也好奇老黄究竟在GTC上带来了什么惊喜吧,别着急,本篇带你一睹GTC峰会上的那些硬件产品。

图片源于网络
见证AI的变革时刻
峰会伊始,我们熟悉的皮衣刀客准时出场。一上来就直奔今天的主题——AI,并表示“加速式计算机的生产力已经到达了一个转折点,生成式AI正在加速发展,而我们需要以一种全新的方式进行计算,才能够进一步提高计算机生产力。”

图片源于网络
并且还贴心的展示了其自己亲手画出的关于计算机生产力的演变流程,最后一项正是今天的重点!
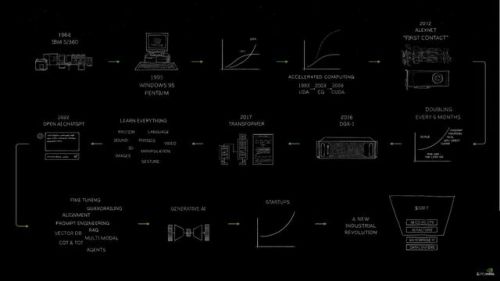
图片源于网络
改变形态的Blackwell GPU
没错,老黄在GTC宣布推出新一代GPU Blackwell。这里先介绍一下Blackwell架构,此前NVIDIA推出的显卡一般是两种架构,其中游戏显卡例如我们熟悉的RTX 40系则是Ada Lovelace架构,而面向AI、大数据等应用的专业级显卡则采用Hopper 架构。

图片源于网络
而老黄在大会上则表示“Blackwell不是一个芯片,它是一个平台的名字。”意思是Blackwell架构将同时用于以上两种类型的产品。借助这一架构,NVIDIA将推出涵盖多个应用领域的显卡,即RTX 50系显卡也会是这个架构。并且从老黄手上的芯片可以看出,新的Blackwell GPU的体积明显比上代Hopper GPU要更大一些。

左边为B100,右边为H100 图片源自于网络
至于这个架构名字的由来,则要追溯到美国科学院首位黑人院士、加州大学伯克利分校首位黑人终身教授戴维·布莱克维尔(David Blackwell),它是著名的数学家、统计学家,不过很可惜的是这位教授在2010年因病去世。

图片源于网络
恐怖的2080亿晶体管
言归正传,让我们继续关注此次Blackwell GPU。“我们需要更大的GPU,如果不能更大,就把更多GPU组合在一起,变成更大的虚拟GPU。”老黄在GTC上也确实这么干了。Blackwell架构的首个GPU为B200,由于目前4nm制程工艺已经接近极限,所以NVIDIA也玩起了“拼图”,B200采用台积电的 4 纳米(4NP)工艺蚀刻而成,由两个芯片通过NVLink 5.0组合在一起,以10TB每秒的满血带宽互联,总的晶体管数量更是达到了恐怖的2080 亿。

图片源于网络
第二代Transformer引擎
除了芯片形态的变化外,Blackwell还有5大创新,首先就是第二代Transformer引擎。它支持FP4和FP6精度计算。得益于此,Blackwell GPU的FP4与FP6分别是Hopper的5倍与2.5倍。

图片源于网络
第五代NVLink互连
第五代NVLink互连则是将多个Blackwell GPU组合起来的重要工具。它与传统的PCIe交换机不同,NVLink带宽有限,可以在服务器内的GPU之间实现高速直接互连。目前第五代NVLink可每个GPU 提供了1.8TB/s双向吞吐量,确保多达576个GPU之间的无缝高速通信。

图片源于网络
RAS可靠性引擎
这个RAS可靠性引擎则是基于AI实现,Blackwell 透过专用的可靠性、可用性和可维护性 (RAS) 引擎,可增加智慧复原能力,及早辨认出可能发生的潜在故障,尽可能缩短停机时间。

图片源于网络
Secure AI安全AI功能
Secure AI负责提供机密运算功能,同时Blackwell也是业界第一款支持EE-I/O的GPU,它可以在不影响性能的前提下,维护你的数据安全,这对于金融、医疗以及AI方面有极大作用。

图片源于网络
专用解压缩引擎
最后一项创新技术则是关于解压缩层面,资料分析和资料库工作流程此前更多是仰赖CPU进行运算。如果放到GPU中进行则可大幅提升端对端分析的效能,加速创造价值,同时降低成本。

图片源于网络
Blackwell配备了专用的解压缩引擎,使用过程中可以配合内置的Grace CPU实现每秒900 GB的双向频宽,并且还能兼顾最新的压缩格式 (如 LZ4、Snappy和Deflate等)。
超级核弹GB200
而两个B200 GPU与Grace CPU结合就成为今天“火热”的GB200超级芯片。这款超级芯片的性能更加惊人,你以为H100已经很快了?不!GB200更快,过去,在90天内训练一个1.8万亿参数的MoE架构GPT模型,需要8000个Hopper架构GPU。现在,你只要2000个Blackwell GPU就可以完成。

图片源于网络
官方称,在标准的1750亿参数GPT-3基准测试中,GB200的性能是H100的7倍,提供的训练算力是H100的4倍。
图片源于网络
不止是性能更快更强,Blackwell GPU还相当节能。还是同样的操作,90天内训练一个1.8万亿参数的MoE架构GPT模型,8000个Hopper GPU要耗费15兆瓦功耗,如今的Blackwell GPU仅需1/4的能耗就能实现。

图片源于网络
如果你需要更强劲的GPU,NVIDIA也面向有大型需求的企业提供成品服务,提供完整的服务器。例如:GB200 NVL72,它将36个CPU和72个GPU插入一个液冷机架中,总共可实现720 petaflops的AI训练性能或1,440 petaflops(1.4 exaflops)的推理。

图片源于网络
与相同数量的72个H100相比,GB200 NVL72的性能绝对是逆天的存在,大模型推理性能可以提升30倍,并且成本和能耗只有前者的1/25。
当然,最炸裂的要数适用于 DGX GB200 的 DGX Superpod,它将八个GB200 NVL72合二为一,总共有288个CPU、576个GPU、240TB内存和11.5 exaflops的FP4计算能力。老黄更是在GTC上直言“DGX Superpod就是AI的革命工厂!”

图片源于网络
结语
以上就是本次GTC 2024的硬件相关报道,可能有玩家会说,怎么没有游戏显卡?其实按照过往惯例,NVIDIA并没有在GTC上推出消费级显卡的习惯。不过本次NVIDIA在GTC 2024上推出的B100显卡所使用的架构是Blackwell,上面我们也讲过了,这是一个跨越数据中心与消费级产品的架构,这也就意味着我们熟悉的GeForce显卡应该也是同一架构的产品,不出意外的话,下半年我们就有望看到心心念念的RTX 50系显卡了!





