在人工智能领域,最重要的三块基石就是数据、算法和算力。
1、数据:AI蓬勃发展主要是得益于大数据的累积以及AI专用算力的大幅增强。
2、算力:过去10年,AI领域主要的算力载体是以国外芯片厂商提供的GPU设备为主,广泛应用于与AI相关的云端产品。而端侧嵌入式 AI 算力载体从 CPU、GPU、DSP发展到ASIC架构,推动了基于深度学习的语音识别、人脸识别、图文识别、AIGC、目标检测、超分辨率、ADAS等技术的广泛应用。
3、算法:模型算法架构持续迭代,Transformer神经网络结构逐渐成为自然语言处理领域的主流,如ChatGPT是其应用之一,主要用于云端产品,各算法厂商开始尝试应用到端侧产品,对端侧算力性能提出了更高的要求,这将推动AI算力的发展。从AI算法模型到端侧AI部署应用的落地,需要解决很多技术问题,如模型转换、量化、推理框架、算子融合、算子适配(自定义算子开发)等等。这不仅需要性能优越的算法模型以及可靠的高性能低消耗(低带宽低内存低功耗)硬件加速器,还需要通过AI编译器把算法模型转化成硬件设备能识别的表达式进行算法部署,再应用到具体的应用场景,满足用户的体验需求。在算法部署过程,算法开发应用算子级API和网络级API、支持量化感知训练模型导入等加速算法开发效率和应用落地效率。
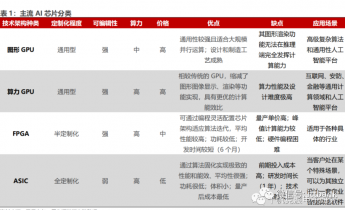
算力也被誉为人工智能心脏。算力芯片及专门用于处理人工智能应用中的大模块。当前算力芯片主要分为GPU、FPGA、ASIC,算力芯片是智能设备里不可缺少的核心器件,专门用来处理AI相关的计算任务。
在AI服务器中,各个部分各司其职,其中:
CPU主要负责逻辑判断,任务调度与控制等基本计算任务;
GPU适用于通用并行计算,能够为AI训练任务提供更高算力;
FPGA具有低延时,开发周期短等特性,可用于AI推理任务等;
ASIC与通用集成电路相比功耗更低性能更优,可用于针对AI训练任务设定特定框架。
算力芯片GPU龙头就是英伟达公司了,英伟达主流AI GPU算力对比如下:
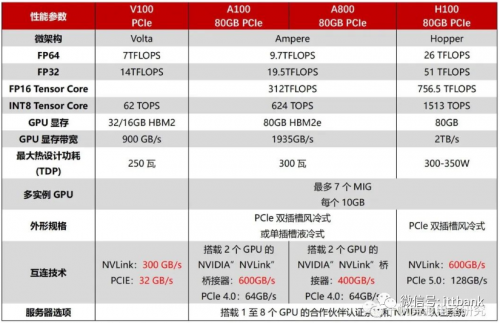 英伟达V100/A100/A800/H100对比
英伟达V100/A100/A800/H100对比
国产AI算力芯片公司有哪些?一起来看看:
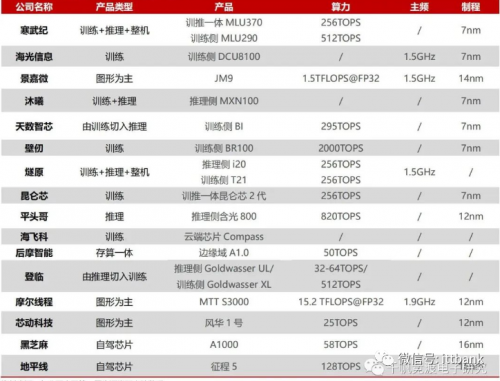 国产 AI 算力芯片公司主要产品对比
国产 AI 算力芯片公司主要产品对比
寒武纪
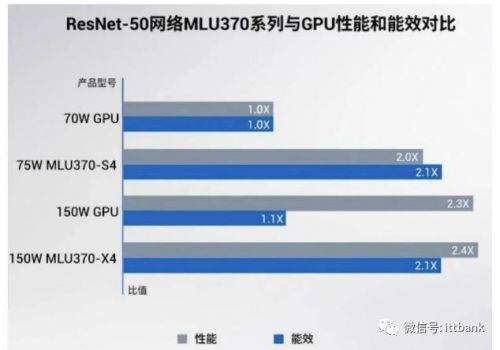
思元370系列板卡与业内主流GPU 性能对比
ASIC-云端AI芯片
22年公司云端产品线实现营收2.2亿元,占总收入30.1%
国内AI芯片龙头;思元290是寒武纪首款云端训练智能芯片;思元370是寒武纪第三代云端智能芯片,采用台积电7nm先进制程工艺,是寒武纪首款采用Chiplet(芯粒)技术的人工智能芯片,最大算力高达256TOPS(INT8),同时基于思元370推出了新款智能加速卡MLU370-X8/M8
思元系列产品已实现规模化销售;在金融领域,与多家头部银行进行了导入和适配;在互联网领域,与阿里巴巴等头部互联网企业的多个业务部门进行了深入合作;在服务器领域,已应用于浪潮、联想等多家服务器厂商的产品中
ASIC-边缘AI芯片
22年公司边缘产品线实现营收3784万元,占总收入5.19%
21年全球市占率0.68%;思元220及相应的M.2加速卡是公司的首款边缘智能芯片产品,在1GHz的主频下,理论峰值性能为32TOPS(INT4)、16TOPS(INT8)、8TOPS,可支持边缘计算场景下的智能数据分析与建模、视觉、语音、自然语言处理等多样化的人工智能应用思元220边缘智能芯片及加速卡成为了公司第一款年度出货量近百万片的产品,在智慧交通的车路协同,智慧电力的线路巡检,智慧医疗的超声筛查等众多场景应用落地
景嘉微
GPU芯片
国内GPU龙头;历经3代升级,第3代GPU产品JM9系列已成功流片,支持OpenGL4.0、HDMI2.0等接口核心频率至少为1.5GHz,配备8GB显存,浮点性能约1.5TFlops,对标英伟达GeForceGTX1050,可以满足目标识别等部分人工智能领域的需求
JM9系列产品已经联合国内主要CPU、整机厂商、操作系统、行业应用厂商等开展适配与调试工作,已逐步实现在政务、电信、电力、能源、金融、轨交等多领域的试点应用
云天励飞
FPGA芯片
17年,第一代神经网络处理器Deep Eye200采用FPGA实现,依托“深目”系统,已经在云天励飞Deep Eye200PCleFPGA加速卡上以及IFBOX边缘计算盒子上应用,主要用于目标识别特征提取
目前已小批量出货
ASIC-视觉AI协处理
18年,第二代神经网络处理器芯片Deep Eye1000采用22nm工艺投片,该芯片主要面向嵌入式前端和边缘计算应用,可实现视频数据的结构化处理,提供2Tops可编程运算能力
于19年起实现独立商用,已与海康威视、阿里巴巴平头哥等建立了业务合作
ASIC-边缘AI芯片
22年,第三代边缘计算芯片Deep Edge10系列SoC芯片成功流片,Deep Edge10采用国内先进工艺、支持多芯粒扩展的Chiplet技术,可提供12TOPS(INT8)整型计算和2TFLOPS (FP16)浮点计算的深度学习推理计算算力,可广泛应用于AloT边缘视频、移动机器人等场景
正在与相关合作方就芯片DeepEdge10开展适配等工作,预计在2023年量产投入使用
壁仞科技
壁仞科技成立于2019年,创始人张文曾任商汤科技总裁,CTO洪洲曾任职于海思的GPU自研团队,软件生态环境主要负责人焦国方曾创建高通公司骁龙GPU团队、领导了5代Adreno GPU架构开发。2021年3月,公司完成B轮融资,累计融资金额超47亿元。2022年8月,壁仞科技发布首款GPGPU芯片BR100,BR100芯片采用chiplet技术,其16位浮点算力达到1000T以上、8位定点算力达到2000T以上。
燧原科技
对于互联网大厂来说,腾讯、百度、阿里巴巴等均在AI芯片领域大力布局。其中,腾讯投资燧原科技、百度投资昆仑芯、阿里巴巴则孵化了平头哥。
燧原科技成立于2018年,公司创始人赵立东曾任紫光通信科技集团有限公司副总裁、AMD计算事业部高级总监;COO张亚林曾任AMD资深芯片经理、技术总监。公司最新发布的第二代推理产品云燧i20是面向数据中心应用的第二代人工智能推理加速卡,采用12nm工艺,通过架构升级大大提高了单位面积的晶体管效率,算力可媲美7nm GPU,达到256TOPS。
恒烁股份
存算一体AI芯片
19年成功设计出第一版CiNORV1芯片(恒芯1号),在武汉新芯65nm NOR Flash制程上流片成功,用于小算力、低功耗应用场景,主要专注在边缘和终端设备上;目前在研CiNORV2芯片(恒芯2号)
正在开展基于MCU的AI应用部署,推动超轻量AI算法模型在MCU芯片上运行,尽快实现批量出货
海光信息
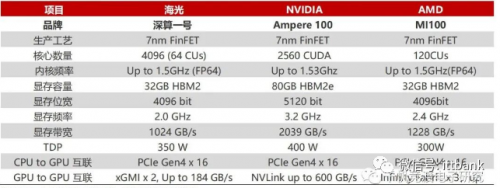 海光深算一号与NVIDIA、AMD产品参数比较
海光深算一号与NVIDIA、AMD产品参数比较
GPU-DCU芯片
22年公司DCU8000系列实现营收2.39亿元,占总收入10.34%
国内DCU龙头;公司深算一号DCU指标性能已接近国际龙头英伟达、AMD;公司DCU产品兼容“类CUDA”环境,能够较好地适配、适应国际主流商业计算软件和人工智能软件,并通过更好的性价比实现国产替代,可广泛应用于大数据处理、人工智能、商业计算等计算密集类应用领域;下一代DCU产品深算二号23年有望量产
21年9月,百度飞桨与海光DCU已经完成互证;22年,海光DCU实现了在大数据处理、人工智能、商业计算等领域的商业化应用,目前已实现规模化出货
复旦微电
FPGA芯片
22年公司FPGA芯片实现营收8.03亿元,占总收入22.69%
国内FPGA领军企业;公司是国内最早推出亿门级FPGA产品的厂商,目前拥有千万门级FPGA、亿门级FPGA及嵌入式可编程器件芯片PSoC共三大系列数十款产品,FPGA可作为算力芯片的一种,在数据中心运算方面的产品形态均为加速卡,在服务器中与CPU进行配合;此外公司正在积极开展14/16nm工艺制程的十亿门级产品的开发
23年4月20日,公司在互动平台表示,FPGA产品的技术水平和客户口碑较好,在手订单充足
安路科技
FPGA芯片
22年公司FPGA芯片实现营收9.88亿元,占总收入94.9%国内FPGA领军企业,19年国内FPGA芯片排名第四,国产品牌排名第一;公司FPGA芯片产品形成了由SALPHOENIX高性能产品家族、SALEAGLE高效率产品家族、SALELF低功耗产品家族组成的产品矩阵,中低端FPGA产品已可对标海外龙头厂商,高端SALPHOENIX系列正逐步追赶海外龙头厂商
在工业控制领域,公司已成功进入了汇川技术、利亚德、灵星雨等知名企业的供应链;在网络通信领域,公司产品于2019年开始导入中兴通讯,是第一批进入中兴通讯供应链的国产FPGA企业之一
澜起科技
存算一体AI芯片
公司AI芯片支持异构多核、高速稳定的互连互通以及不x86软硬件生态的无缝兼容,提升了AI推理计算和大数据吞吏应用场景下的运算效率,未来的目标市场是在医疗领域生物医学/医疗大图片流处理及人工智能物联网领域的大数据应用
已完成第一代AI芯片工程样片的流片并成功点亮,目前正在进行内部测试和验证等相关工作
内存接口芯片
全球可提供DDR4内存接口芯片的三家主要厂商之一,也是目前全球唯二可提供DDR5内存模组及接口芯片全套解决方案的公司;第三子代RCD芯片于22年12月宣布开始送样,其支持数据速率高达6400MT/s,特别适用于大数据、人工智能、物联网、边缘计算等数据密集型应用
客户主要为内存模组厂商及服务器OEM/ODM厂商等
航宇微
ASIC-通用AI芯片
22年AI芯片及算法实现营收286.4万元,占总收入0.67%
玉龙810是公司推出的新一代嵌入式人工智能系列处理器芯片,可以实现12tops的算力,能够实现与TensorFlow,Caffe等主流深度学习软件框架的无缝对接,具有超高稳定性和超低功耗,主要面向航空航等应用场景玉龙810开发板及芯片经过客户的大量测试和验证,得到了好评,并实现了销售合同的逐步签订
国芯科技
GPU芯片
公司和参股公司智绘微合作,联合投资和开发GPU芯片,该芯片将着重于图形渲染和人工智能应用
该GPU芯片已完成设计,目前正在流片验证中,未来将以国芯科技和智绘微双品牌进行市场销售
Raid芯片
国内极少数拥有RAID控制芯片的厂商;目前公司已推出第一代Raid控制芯片,开发的Raid芯片和板卡将可以应用于AI服务器系统基于Raid控制芯片的改进版已成功进行内部测试,基于RISC-V的第二代更高性能RAID控制芯片正顺利开发中
紫光国微
FPGA芯片
国内FPGA领军企业;子公司紫光同创有Titan系列高性能FPGA、Logos系列高性价比FPGA、Compa系列CPLD共3个系列可编程逻辑器件产品,广泛应用于通信、图像视频处理、数据分析、网络信息安全;第二代SOPC面向人工智能、机器视觉等领域,已经启动研发
目前大规模FPGA/CPLD已实现量产发货,中小规模FPGA产品型号进一步完善
国科微
AI视觉处理芯片
公司于22年9月定增,总投资10.7亿元用于研发AI视觉处理芯片产品,目前研发正常推进中,未来应用在安防、机器视觉中初期产品预计23年推出市场并服务客户,为公司营收做出贡献
芯原股份
GPU-NPU IP
22年FPGA业务收入15亿元半导体IP授权服务国内第二,全球第七;AI视频处理解决方案、GPGPU和NPU也已经被用于客户面向数据中心、高性能计算、汽车等领域的AI芯片中
用于人工智能的神经网络处理器IP(NPUIP)已经在10多个领域、60多家客户的110多款芯片中被采用,包括应用于谷歌多款智慧家居产品
中科曙光
GPU-DCU芯片
持有海光信息27.96%的股份,海光信息系国内DCU龙头;海光信息的深算一号DCU指标性能已接近国际龙头英伟达、AMD;海光信息DCU产品兼容“类CUDA”环境,能够较好地适配、适应国际主流商业计算软件和人工智能软件,并通过更好的性价比实现国产替代,可广泛应用于大数据处理、人工智能、商业计算等计算密集类应用领域
21年9月,百度飞桨与海光DCU已经完成互证;22年,海光DCU实现了在大数据处理、人工智能、商业计算等领域的商业化应用,目前已实现规模化出货
创耀科技
通信芯片-接入网终端、局端芯片,WiFi AP芯片
公司的终端芯片是调制解调器、路由器及网关等网络终端设备内的主芯片;已量产的局端芯片,包含局端设备DSLAM的接口卡核心芯片及配套芯片;无线接入网领域产品涉及WiFi芯片及路由芯片,公司WiFi AP芯片主要用于路由器、网关等网络通信设备,可支持更高的带宽、通信速率和用户数量
公司产品和服务主要应用于烽火通信、共进股份、D-Link、Iskratel、Alpha、亿联和中广互联等知名通信设备厂商以及英国电信、德国电信和西班牙电信等大型海外电信运营商
裕太微
通信芯片-以太网物理层芯片
22年以太网物理层芯片业务收入3.56亿元,占总收入88.39%国内少数可以大规模供应千兆高端以太网物理层芯片的企业;已开发了系列千兆物理层芯片,产品性能对标国际巨头博通、美满电子和瑞昱的同类产品,可满足信息通讯、汽车电子、消费电子、监控设备、工业控制等多个领域的需求
以太网物理层芯片在2021年实现大规模销售,已成功进入普联、盛科通信、新华三、海康威视、汇川技术、诺瓦星云、烽火通信、大华股份等国内众多知名企业的供应链体系
沐曦集成电路
沐曦集成电路成立于2020年,公司创始团队处于国内顶尖行列——创始人陈维良曾任AMD全球GPGPU设计总负责人;两位CTO均为前AMD首席科学家,目前分别负责公司软硬件架构;核心成员平均拥有近20年高性能GPU研发经验。沐曦于2022年7月完成10亿元Pre-B轮融资,由混沌投资领投。沐曦首款异构GPU产品MXN100采用7nm制程,已于2022年8月回片点亮,主要应用于推理侧;应用于AI训练及通用计算的产品MXC500已于2022年12月交付流片,公司计划2024年全面量产。
天数智芯
天数智芯成立于2015年,首席科学家郑金山为原AMD首席工程师,首席技术官Chien-Ping Lu曾任三星全球副总裁。2022年7月,公司完成超10亿元人民币的C+轮及C++轮融资。天数智芯的Big Island云端GPGPU是一款具有自主知识产权、自研IP架构的7nm通用云端训练芯片,这款芯片达到295TOPS INT8算力。
注:转载至网络文中观点仅供分享交流,不代表贞光科技立场,如涉及版权等问题,请您告知,我们将及时处理!