文:Apple
编:亦可
大模型的风在吹了半年后,终于有了新方向。
7月7日,在2023世界人工智能大会(WAIC 2023)上,由国家标准委指导的人工智能标准化总体组宣布,我国首个大模型标准化专题组组长由上海人工智能实验室与百度、华为、阿里等企业联合担任。
对于首批入选的“国家队”阵容,外界并不意外,毕竟大模型的发展,需要靠技术实力格外雄厚的玩家引领。而在国家明确他们的地位及任务后,国内大模型市场的风向,开始有了新变化。
01
狂飙半年,行业迎来“国家队”
今年以来,大模型一路狂飙,速度超过了以往任何一项技术的发展进程。如果说在今年一季度,各个玩家蜂拥至大模型的入口,还在讨论“要不要做”的问题,到了二季度时,各家已经进化到具体“怎么做”的问题上来。
而这样的热闹场景,在WAIC 2023上迎来了高潮。这届大会超400家企业参展、30多个大模型集中亮点,展区面积达到了5万平方米,创下了历届之最。
这场热闹的大会,不少人因为没有提前预约而无法进入大会现场。在被行业人士称为“规格”很高的大会上,网红马斯克、图灵奖三巨头之一的杨立昆、华为轮值董事长胡厚昆、香港中文大学教授汤晓鸽,以及学界、创业界的大佬们纷纷到场。
展厅内,大模型时代、生成式AI、通用人工智能,这些在半年前还很陌生的词汇,如今成为展厅里随处可见的标志。
当然,大会现场的30余家大模型的玩家们,也并没有让外界失望,纷纷给出了自己对于大模型的解答。尤其是“国家队”成员的动作,更是令外界瞩目。
比如百度,作为国内首家宣布All in人工智能的厂商,其在大会现场的展厅格外吸引人。当然,在这个重要的场合,百度自然会展出让更多人能体验到的“镇馆之宝”,这个被称为文心一格的产品,可以让进入展厅的观众实现P图自由。
华为则将其“全球最快AI训练集群”Atlas 900 PoD A2搬到了现场。华为副董事长胡厚崑称,使用 Atlas 900,人们只需 59.8 秒就可以完成典型神经网络 ResNet-50 在 ImageNet 数据集上的训练,在同等精度下比第 2 名快 15%。“这相当于在短跑赛场上头名撞线,然后喝完一瓶水才看到第二名跑到终点。”无疑,华为这场硬件端基础算力的实力大秀,使得行业人士和观众将视线从大模型的繁杂移至硬件端的比拼。
在阿里云论坛,阿里云“通义家族”再添AI绘画模型“通义万相”,据称,该模型可辅助人类进行图文创作,未来可应用于艺术设计、电商、游戏和文创等应用场景。阿里云智能集团CTO周靖人在现场表示,这是阿里云大模型全面掌握多模态能力的关键一步,未来这一能力还将逐步向行业客户开放。

“有钱、有人、有技术、有场景”,这是大厂做大模型先天具备的优势,同时也是不少初创企业很难填平的鸿沟,甚至有人在现场直接指出,中国的大模型落地,只会在五家大厂之中,即BAT+华为+腾讯。
但巨头们要怎么做?下一步会走向何方,这是一个很大的命题。
02
抛弃概念与情怀,巨头纷纷专注于场景落地
今年的人工智能大会,大模型成为当之无愧的顶流。
阿里通义、百度文心、华为盘古等国家队纷纷亮出自己的硬实力,同时,讯飞星火、商汤日日新、网易伏羲等30多个垂类大模型也没有输掉气势,在各自的领域里埋头苦干。
但从现场的情况来看,他们似乎已经摒弃了大而空、讲故事、讲情怀的做法,转而开始专注于讲落地场景和案例。这是大模型前进的必由之路,同时也极有可能成为下一阶段的重头戏。
在大会上,华为云盘古大模型3.0正式发布,引来不少行业人士围观。更令行业印象深刻的在于,华为常务董事、华为云CEO张平安所言——盘古大模型很忙,忙着做事,没有时间作诗。而作诗,正是此前半年发布大模型的玩家们最爱干的事。在张平安看来,华为希望盘古大模型可以帮助各行各业,如金融、政务、矿山、气象等,而非专注在语言大模型层面。据其透露,截至目前,盘古大模型已经在气象、医药研发、电力等领域落地,并交付了多个千亿参数大模型。
同样把场景落到实处的还有百度。百度作为较早入局的玩家,早在四年前即发布文心大模型,只是当时行业对于大模型的关注度不够,以至于没有激起太多水花。但对于百度而言,文心大模型是先行业一步的超前布局。如今,这个前瞻的产品也收获颇丰。

在WAIC 2023现场,百度首席技术官王海峰称,现在百度已经升级到文心大模型3.5版本,较之此前的版本,效果提升50%、训练速度提升2倍,推理速度提升了30倍。在成本上,更是降到过去的10%。
“把促进中国大模型生态的繁荣作为首要目标,向大模型创业公司提供全方面的服务”。阿里云CTO周靖人如此说道。很明显,这延续了阿里云提出的MaaS(模型即服务)概念。
在大模型领域最晚入局的腾讯,最近20天内动作不断。6月19日,腾讯首次公开透露对大模型的思考;6月26日,首次披露自研星脉高性能计算网络;在7月7日WAIC 2023上,腾讯云副总裁、腾讯云智能负责人吴运声对外公开了腾讯在大模型应用创新的成果,并称,腾讯云行业大模型能力已应用到金融风控、交互翻译、数智人客服等场景中,提升了智能应用效率。
当然,细分领域的大模型也展现出旺盛的生命力。旷视科技联合创始人、CTO唐文斌在接受媒体采访时说道:“应用落地是衡量大模型价值的唯一标准,旷视科技会从视觉大模型向通用多模态大模型进军。”
专注场景落地,切实为企业用户提供降本增效的方案,成为当下大模型玩家集中发力的点。而未来,大模型早已从“做与不做”,真正迈进了“做得怎么样”的问题。而这正是大模型之争的下一步。
03
参与未来之争,先回答这四个问题
虽然大模型很火,但从开局到推向市场,中间还有很远的一段路要走。在此过程中,很多难点已然暴露出来。
不过,在壹DU财经看来,大模型的未来之争,多半会在四个纬度展开。即:技术、人才、资金以及商业化落地。
首先看技术层面。毫无疑问,人工智能是当前最为先进的技术之一,在技术层面,其所需要的积淀不可能在短时间内补齐。“大”算力、“大”数据、“大”模型是目前大模型的基本特征,同时也是大模型的产业化落地面临的挑战,目前来看,数据规模虽大,但数据质量参差不齐。其次,模型的体积大,训练难度更高,第三是算力规模大,对硬件性能要求会更高。
这也意味着,没有足够的资金作为支撑,很难组建这样一个超强的战队。一位营销云创始人与壹DU财经沟通时曾提到:“从3月份投入做行业大模型以来,整体资金投入非常大,甚至超过了公司成立到做大模型之前的总和。”不过,他也提到,如果做成了,对于公司的未来十年发展,绝对是定心丸。
在此之前,不少行业人士就曾提出“大模型是大厂烧钱的游戏”。这种说法并非毫无道理。
虽然大模型很火,但全球范围来看,资本却未跟上技术复苏的节奏。研究公司PitchBook的数据称,今年前六个月,全球风险投资资金几乎减少了一半,下降48%至1739亿美元,交易数量也下降了19%。
在中国,截至今年6月底,有十几家大模型初创公司获得融资,在已经公布融资额的企业中,融资规模最大的是MiniMax,今年6月获得腾讯公司超过2.5亿美元A轮融资;光年之外在被美团收购前,也获得了2.3亿美元的天使+轮融资。
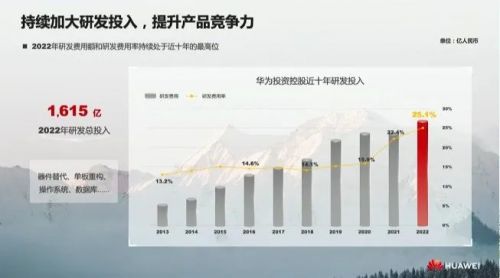
再来看大厂的投入情况,此前,钛媒体的统计数据颇能说明问题,2022年,华为在研发费用上投入为1615亿元,成为国内研发投入最多的企业;其次是腾讯,虽然低了不少,但也保持在614亿元的水平,阿里排在第三,研发费用为555亿元。公开资料显示,百度作为较早入局人工智能的玩家,过去十年,其在AI领域的投入超过1000亿元。这样的投入规范,显然不是一般企业可以比拟的。
有技术、有资金,大厂们对于人才的吸引力相对更强。今年年初,各家开始了疯狂的人才抢夺战。百度以25-40K的月薪招聘AI大模型算法工程师,更阔气的阿里以40-70K的月薪招募大模型训练及算法工程师。
在某招聘平台上搜索关键词“大模型”后,会发现,一些企业愿意给到2023届毕业生15-25K月薪的待遇。同时,一些垂直赛道的企业也参与了这轮抢人大战。比如某贸易公司招聘的医疗大模型产品经理,薪资范围为25-50K,某游戏公司招聘语言大模型的算法工程师,也给到了最高50K的薪资。甚至中国电信招聘的大模型平台产品经理年薪可以达到84万的水平。
水涨船高的人才、技术以及资金,无不催促着大模型的玩家们尽快落地、尽快商业化,毕竟,按照商业规律,最终这些投入需要产出回报,才有价值。
但大模型的落地成本,同样是各大玩家需要跨过的槛。曾有行业人士估算,大模型训练一次的成本极高,达到了200-12000万美元。这也意味着,AI大模型的商业化落地,可能还得回到成本核算这件事上。
结语
站在当下看大模型,整体很像1998年的互联网,初于起步阶段,泡沫很大,机会也很大。在这种情况下,真正有实力的好公司,未来的成长性会更好,价值也会越来越大。
图片来源于公开网络,侵删。
原文标题 : “国家队”下场,大模型“卷”向新纬度






