背景
社交媒体平台是分享有趣的图像的常用方式。食物图像,尤其是与不同的美食和文化相关的图像,是一个似乎经常流行的话题。Instagram 等社交媒体平台拥有大量属于不同类别的图像。我们都可能使用谷歌图片或 Instagram 上的搜索选项来浏览看起来很美味的蛋糕图片来寻找灵感。但是为了让这些图片可以通过搜索获得,我们需要为每张图片设置一些相关的标签。
这使得搜索关键字并将其与标签匹配成为可能。由于手动标记每张图像极具挑战性,因此公司使用 ML (机器学习)和 DL (深度学习)技术为图像生成正确的标签。这可以使用基于一些标记数据识别和标记图像的图像分类器来实现。
在本文中,让我们使用 fastai 构建一个图像分类器,并使用一个名为“ fastai”的库来识别一些食物图像。
Fastai 简介
Fastai 是一个开源深度学习库,它为从业者提供高级组件,可以快速轻松地在传统深度学习领域产生最先进的结果。它使研究人员可以混合和组合低级组件以创建新技术。它旨在在不影响可用性、灵活性或性能的情况下实现这两个目标。
由于 fastai 是用 Python 编写的,并且基于 PyTorch,因此需要 Python 知识才能理解本文。我们将在 Google Colab 中运行此代码。除了 fastai,我们将使用图形处理单元 (GPU) 以尽可能快地获得结果。
使用 Fastai 构建图像分类器
让我们从安装 fastai 库开始:
!pip install -Uqq fastai
如果你使用的是 Anaconda,请运行以下命令:
conda install -c fastchan fastai anaconda
让我们导入分类任务所需的包。该库分为模块,其中最常见的是表格、文本和视觉。因为我们手头的任务包括视觉,所以我们从vision库中导入我们需要的所有功能。
from fastai.vision.all import *
通过 fastai 库可以获得许多学术数据集。其中之一是 FOOD,它是 URL 下的URLs. FOOD
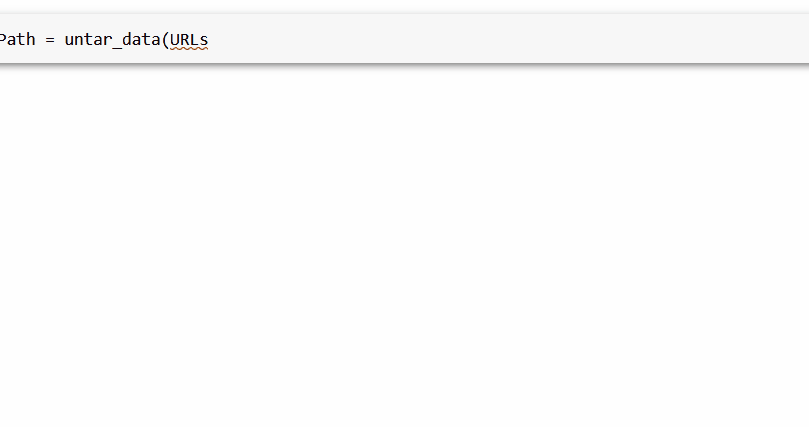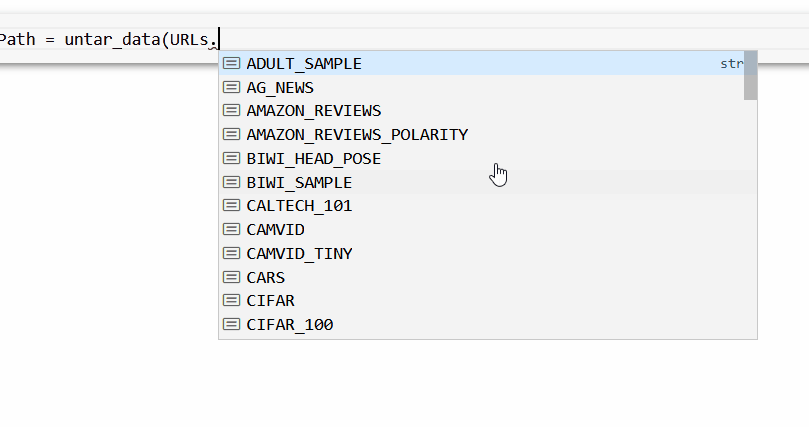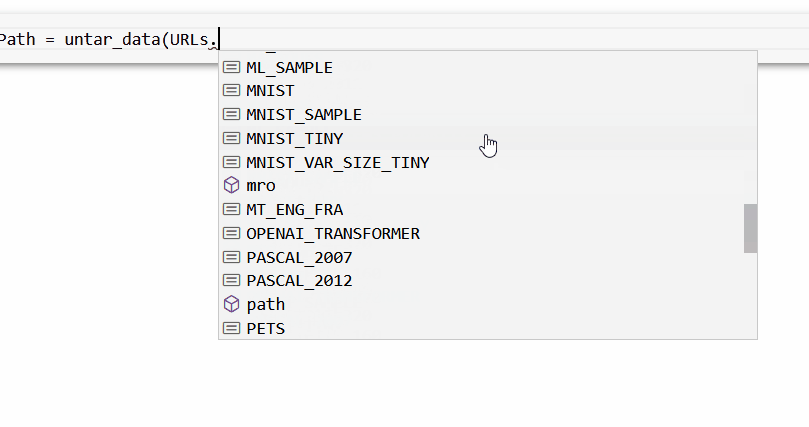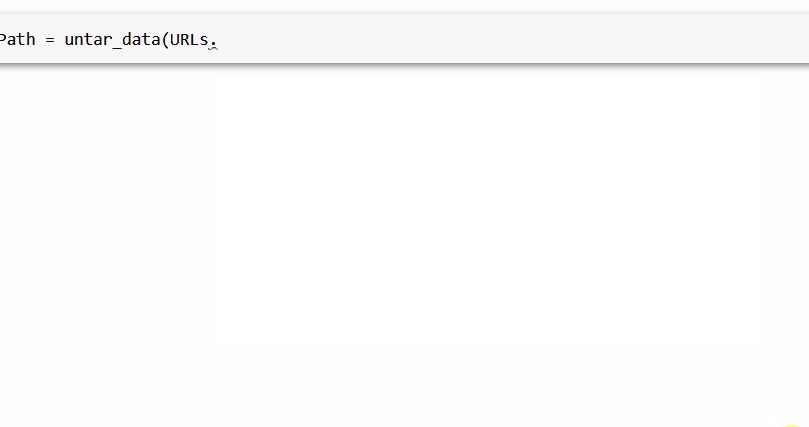
第一步是获取并提取我们需要的数据。我们将使用 untar_data 函数,它会自动下载数据集并解压它。
foodPath = untar_data(URLs.FOOD)
该数据集包含 101,000 张图像,分为 101 个食物类别,每个类别有 250 个测试图像和 750 个训练图像。训练中的图像没有被清理。所有图像的大小都调整为每边最大 512 像素。
下一个命令将告诉我们必须处理多少图像。
len(get_image_files(foodPath))
此外,使用以下命令,我们将打印 Food 数据集的元目录的内容。
print(os.listdir(foodPath))
meta文件夹包含八个文件,其中四个是文本文件:train.txt、test.txt、classes.txt和labels.txt。train.txt 和 test.txt 文件分别包含训练集和测试集的图像列表。classes.txt 文件包含所有食品类别和标签的列表。txt 提供了所有食品图像标签的列表。该目录还包含一个带有预训练模型的 .h5 文件和一个包含 101,000 张 JPG 格式图像的图像文件夹。最后,训练集和测试集以 JSON 格式提供。
要查看所有图像类别,我们将运行以下命令:
image_dir_path = foodPath/'images'
image_categories = os.listdir(image_dir_path)
print(image_categories)
然后,我们将执行以下命令以查看 101,000 张图像集合中的示例图像。
img = PILImage.create('/root/.fastai/data/food-101/images/frozen_yogurt/1942235.jpg')
img.show();

我们将使用 pandas 函数读取 JSON 格式的训练和测试文件。JSON 是一种以人类可读的形式存储信息的数据格式。
以下代码从目录中读取 train.json 文件并将结果保存在 df_train 数据帧中。
df_train=pd.read_json('/root/.fastai/data/food-101/train.json')
然后可以使用 head() 函数打印数据帧的标题,如下所示。
df_train.head()

同样,通过使用 pandas 函数,我们将读取 test.json 文件并将其存储在 df_test 数据帧中。
df_test=pd.read_json('/root/.fastai/data/food-101/test.json')
df_test.head()
我们正在创建三个带有我们选择的食物名称的标签来对食物图像进行分类。
labelA = 'cheesecake'
labelB = 'donuts'
labelC= 'panna_cotta'
现在我们将创建一个 for 循环,它将遍历我们下载的所有图像。在此循环的帮助下,我们将删除没有标签 A、B 或 C 的图像。此外,我们使用以下函数重命名具有各自标签的图像。
for img in get_image_files(foodPath):
if labelA in str(img):
img.rename(f"{img.parent}/{labelA}-{img.name}")
elif labelB in str(img):
img.rename(f"{img.parent}/{labelB}-{img.name}")
elif labelC in str(img):
img.rename(f"{img.parent}/{labelC}-{img.name}")
else: os.remove(img)
让我们使用以下命令检查运行循环后获得的图像数量:
len(get_image_files(foodPath))
让我们在三个选择的食物中尝试一个示例标签,看看重命名是否正确。
def GetLabel(fileName):
return fileName.split('-')[0]
GetLabel("cheesecake-1092082.jpg")
以下代码生成一个 DataLoaders 对象,该对象表示训练和验证数据的混合。
dls = ImageDataLoaders.from_name_func(
foodPath, get_image_files(foodPath), valid_pct=0.2, seed=42,
label_func=GetLabel, item_tfms=Resize(224))
dls.train.show_batch()

在这种情况下,我们将:
· 使用路径选项指定下载和提取数据的位置。
· 使用 get_image_ files 函数从指定位置收集所有文件名。
· 对数据集使用 80–20 拆分。
· 使用 GetLabel 函数从文件名中提取标签。
· 将所有图像调整为相同大小,即 224 像素。
· 使用 show_batch 函数生成一个输出窗口,显示带有指定标签的训练图像网格。
是时候将模型放置到位了。使用 ResNet34 架构,我们将通过专注于称为 vision_learner () 的单个函数调用来构建卷积神经网络。
vision_learner 函数(也称为 cnn_learner)有利于训练计算机视觉模型。它包括你的原始图像数据集、预训练模型 resnet34 和一个度量错误率,它决定了在验证数据中错误识别的图像的比例。resnet34 中的 34 指的是这种架构类型中的层数(其他选项有 18、50、101 和 152)。使用更多层的模型需要更长的训练时间并且更容易过度拟合。
Fastai 提供了一个“fine_tune”函数,用于调整预训练模型,以使用我们选择的数据解决我们的特定问题。为了训练模型,我们将 epoch 数设置为 10。
learn = vision_learner(dls, resnet34, metrics=error_rate, pretrained=True)
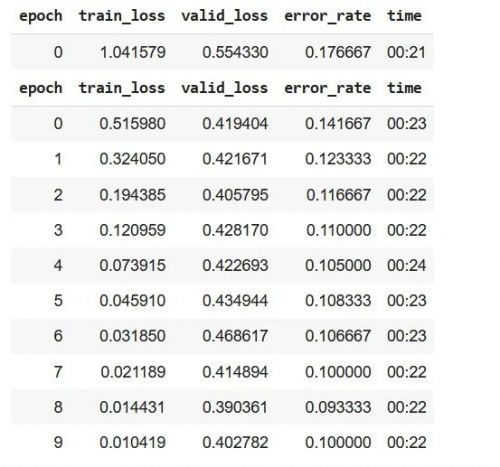
learn.fine_tune(epochs=10)
也可以通过将指标替换为“accuracy”来检查相同模型的准确性。
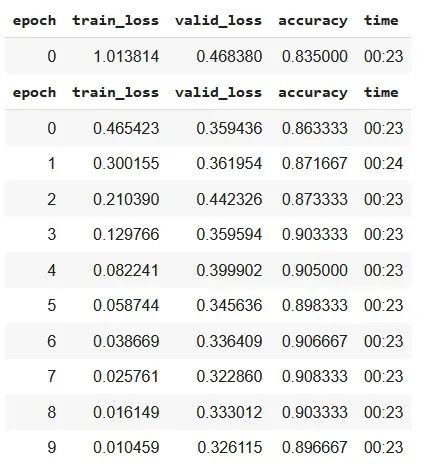
从上面的结果,我们可以说,即使只有 10 个 epoch,预训练的 ResNet34 模型在多标签分类任务中表现出 > 85% 的良好准确率。如果我们增加 epoch 的数量,模型的准确性可能会提高。
现在,让我们测试一些示例图像来检查我们的模型的性能。
示例图片 #1

示例图片 #2

示例图片 #3

从上面的结果,我们可以说我们的模型能够正确识别样本图像。
训练模型后,我们可以将其部署为 Web 应用程序供其他人使用。尽管 fastai 主要用于模型训练,但你可以使用“learn.export”函数快速导出 PyTorch 模型以用于生产。
结论
在本教程中,我们学习了如何使用基于 PyTorch 的 fastai 构建食物图像分类器。可以使用 Heroku 或 Netlify 等服务部署此模型,以使此模型可用作 Web 应用程序。
以下是本文的一些主要内容:
我们可以使用 fastai 以最少的代码建立深度学习模型。因此,fastai 使得使用 PyTorch 进行深度学习任务变得更加容易。
食品分类对于计算机视觉应用来说是一项具有挑战性的任务,因为根据装饰和供应方式的不同,同一种食品在不同地方看起来可能会有很大差异。尽管如此,通过利用迁移学习的力量,我们可以使用预训练模型来识别食品并对其进行正确分类。
我们为此分类器使用了预训练模型 ResNet34。但是,你可以使用其他预训练模型,如 VGG、Inception、DenseNet 等,来构建你自己的模型。
原文标题 : 使用 Fastai 构建食物图像分类器